
一.JVM
1.JVM 内存模型
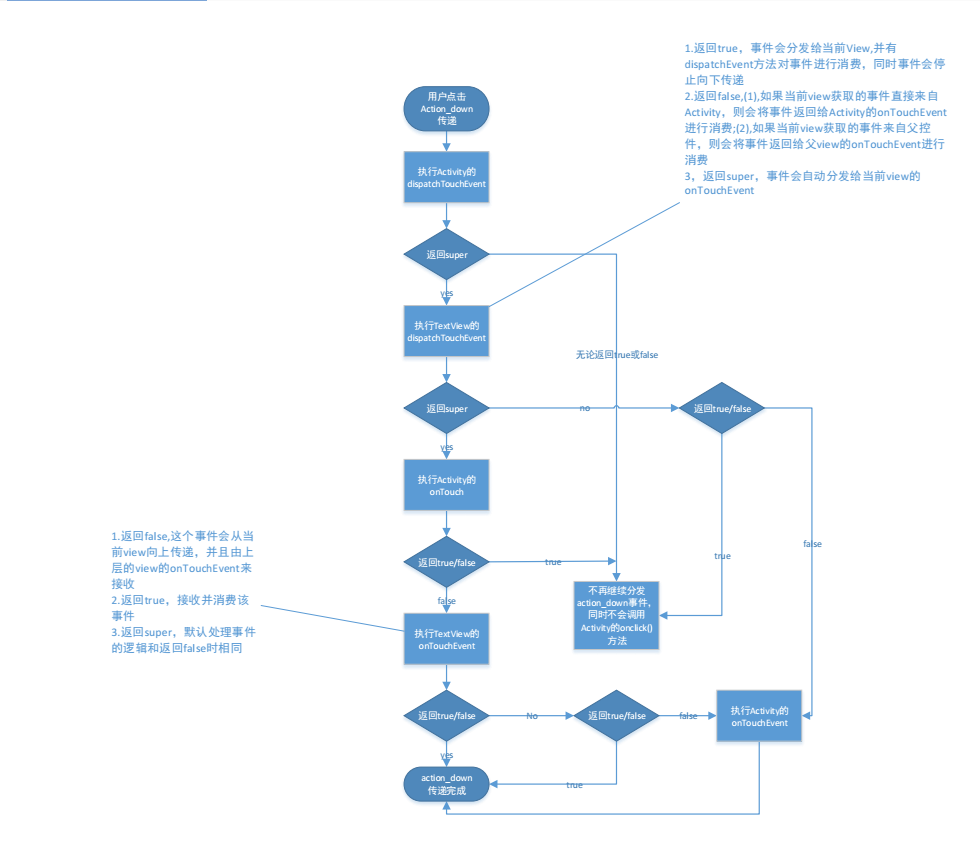
JVM 的内存模型指的是 Java 程序在 JVM 中运行时,JVM 给程序分配的内存结构。JVM 的内存模型主要分为以下几个区域:
- 方法区(Method Area):也称为永久代(PermGen),用于存放类的元信息,如类名、方法名、访问修饰符等,以及运行时常量池。
- 堆(Heap):JVM 中最大的一块内存区域,用于存放对象实例。堆的大小可以通过启动参数来设置。
- 栈(Stack):每个线程都会分配一个栈,用于存放线程私有的方法调用和局部变量等信息。
- 本地方法栈(Native Stack):用于执行本地方法(Native Method)的栈。
- PC 寄存器(Program Counter):用于存放正在执行的指令地址。
- 垃圾回收堆(Garbage Collection Heap):与堆的功能相同,但是用于存放临时生成的垃圾对象。
以上六个区域中,方法区和堆是所有线程共享的区域,其他区域是线程私有的。JVM 对这些区域分别进行管理和分配,以保障程序的正确执行和内存的有效使用。
需要注意的是,JVM 对堆的实现方式可能有所不同,如使用分代垃圾回收算法等。此外,JVM 的内存模型也会随着 JVM 版本的更新和改变而有所改变。
2.以下是几个常见的 JVM 相关面试题及其答案:
Q:什么是 JVM?
A:JVM 指的是 Java 虚拟机(Java Virtual Machine),是 Java 应用程序在多平台上运行的核心部分。JVM 负责将编译后的 Java 代码解释运行,并进行垃圾回收等管理和优化操作。
Q:JVM 的工作原理是什么?
A:JVM 的工作原理主要包括以下几个方面:
- 将编译后的 Java 代码加载到内存中。
- 将字节码解释成机器码,再运行在计算机上。
- 进行垃圾回收,并释放不再使用的内存空间。
- 对代码进行 JIT(Just-In-Time)编译优化,从而提高程序的执行效率。
Q:JVM 内存分为哪几个区域?
A:JVM 内存分为以下几个区域:
- 方法区(Method Area):存储加载的类信息、常量、静态变量和方法字节码等。
- 堆(Heap):存储所有实例对象,包括 Java 类库和应用程序本身创建的对象。
- 栈(Stack):存储线程私有的方法栈、堆栈帧和局部变量等信息。
- 本地方法栈(Native Stack):为执行本地方法提供支持。
- PC 计数器(Program Counter):存储当前线程执行的字节码指令地址。
Q:如何进行 JVM 调优?
A:JVM 调优主要包括以下几个方面:
- 合理设置 JVM 内存大小,避免出现内存溢出等问题。
- 优化垃圾回收机制,避免频繁的 Full GC。
- 避免过度使用同步和锁,优化多线程并发性能。
- 使用合适的数据结构和算法,减少程序的时间和空间复杂度。
- 对代码进行优化,比如使用内联函数、避免过度继承、减少方法调用等。
Q:什么是内存溢出和内存泄漏?
A:内存溢出指的是应用程序申请内存空间时,无法分配到所需的空间,从而导致程序崩溃。内存泄漏指的是应用程序在使用完内存后,未及时释放该内存空间,导致内存的浪费和不足。
Q:JVM 如何进行垃圾回收?
A:JVM 垃圾回收主要采用的是标记-清除、复制、标记-压缩等算法,其中标记-清除算法是最基本的垃圾回收算法。具体来说,JVM 首先标记哪些对象需要回收,然后清理掉这些对象所占用的内存空间,最后再进行一次内存整理,将存活的对象整理到一起,释放出可用空间给新分配的对象使用。
一.GC
以下是几个常见的 JVM GC 相关面试题及其答案:
Q:什么是垃圾回收?
A:垃圾回收指的是在程序执行过程中,自动回收不再使用的内存空间,避免程序出现内存泄漏等问题。
Q:JVM 垃圾回收是什么?
A:JVM 垃圾回收指的是 JVM 进程自动对不再使用的内存空间进行回收和清理,释放出可用的内存空间。
Q:JVM 中的垃圾回收算法都有哪些?
A:JVM 中的垃圾回收算法包括以下几种:
- 标记-清除算法(Mark-Sweep):将不再使用的对象标记为垃圾,然后清理掉这些对象所占用的内存空间。
- 复制算法(Copy):将堆分成两个区,每次只使用其中一个区,当其中一个区的空间已满时,将存活的对象复制到另一个区,然后清理掉原来的区域。
- 标记-压缩算法(Mark-Compact):标记不再使用的对象,然后压缩存活的对象,使它们尽可能地占用连续的内存空间。
- 分代收集算法(Generational Garbage Collection):将堆内存分为新生代和老年代,使用不同的回收算法进行回收,优化回收效率。
Q:JVM 中如何进行垃圾回收?
A:JVM 中的垃圾回收过程通常包括以下几个步骤:
- 标记需要回收的对象。
- 清理掉需要回收的对象,释放内存空间。
- 将存活的对象整理到一起,压缩占用的内存空间。
- 分代收集时,将新生代和老年代分别进行垃圾回收。
Q:JVM 中如何避免垃圾回收带来的性能问题?
A:在 JVM 中,尽量避免不必要的垃圾回收可以提高程序的性能。具体可以采用以下措施:
- 合理设置 JVM 内存大小,避免频繁的内存溢出和垃圾回收。
- 使用不会产生大量垃圾的数据结构和算法,减少内存的占用。
- 避免频繁的对象创建和销毁,优化程序的设计和实现。
- 避免频繁的对象引用和复制,尽量使用不变对象和缓存机制等。
Q:JVM 中如何手动触发垃圾回收?
A:在 Java 代码中,可以通过调用 System.gc() 方法来手动触发垃圾回收。需要注意的是,手动触发垃圾回收并不一定能提高程序的性能,而且也可能会影响程序的执行效率。
一.LRU-Cache
- 什么是 LRU Cache?
LRU Cache 指最近最少使用缓存,它是一种常见的缓存管理技术,用于加速数据访问。LRU Cache 基于最近使用的记录在缓存中保留一个固定大小的记录集,并剔除最近最少使用的记录。当缓存中的记录数量达到上限时,最早之前被使用的记录会被替换掉。
- 你是如何实现一个 LRU Cache?
一个简单实现 LRU Cache 的方法是维护一个哈希表以及一个双向链表。哈希表用于记录每个记录的位置和值,而双向链表用于记录记录的顺序。当一个新记录被访问时,在哈希表中查找该记录,如果记录存在则将其移动到链表的头部;如果记录不存在,就将其添加到哈希表和链表的头部。如果缓存已满,则将链表的末尾元素从哈希表和链表中移除。
- LRU Cache 的时间复杂度是多少?
LRU Cache 的时间复杂度主要取决于两个因素:哈希表的查找复杂度和双向链表操作的复杂度。在哈希表的查找方面,时间复杂度为 O(1);在双向链表操作的方面,插入、删除和移动操作的时间复杂度也为 O(1)。因此,整个 LRU Cache 的时间复杂度为 O(1)。
- 你如何优化 LRU Cache?
一些优化 LRU Cache 的方法包括:
- 使用高效的哈希表实现,例如 Cuckoo 哈希表;
- 将链表的节点保存在一个数组中,以便更快地访问链表中的元素;
- 使用类似于时间轮的数据结构来处理过期的缓存项。
- 除了 LRU Cache 外,你还学过哪些缓存算法?
除了 LRU Cache 外,一些其他常见的缓存算法包括:
- 最少频繁使用(LFU)缓存算法;
- 先进先出(FIFO)缓存算法;
- 随机缓存算法。

Monitore o celular de qualquer lugar e veja o que está acontecendo no telefone de destino. Você será capaz de monitorar e armazenar registros de chamadas, mensagens, atividades sociais, imagens, vídeos, whatsapp e muito mais. Monitoramento em tempo real de telefones, nenhum conhecimento técnico é necessário, nenhuma raiz é necessária.
Wow superb blog layout How long have you been blogging for you make blogging look easy The overall look of your site is magnificent as well as the content
qiyezp.com
메뚜기 떼와 같은 무수한 화살이 하늘에서 호의 반을 가로질렀다.
buysteriodsonline.com
반면 팡지판은 침착하게 앞으로 나아가며 “폐하…”라고 말했다.
qiyezp.com
Fang Jifan은 이상하게 말했습니다. “그의 전하는 실제로 이렇게 우아한 분위기를 가지고 있습니다.”
animehangover.com
Hongzhi 황제는 손을 잡고 미소를 지으며 말했습니다. “왕자는 그렇게 기뻐할 필요가 없습니다.”